

mybatisv3.3.0免费版
- 软件大小:4.17 MB
- 更新日期:2021-12-04
- 软件语言:简体中文
- 软件类别:国产软件
- 软件授权:免费软件
- 软件官网:未知
- 适用平台:Windows10, Windows8, Windows7, WinVista
- 软件厂商:

软件介绍 人气软件 相关文章 网友评论 下载地址
mybatis和hibernate的区别
1.HibernateHibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用,最具革命意义的是,Hibernate可以在应用EJB的J2EE架构中取代CMP,完成数据持久化的重任。
2.MyBatis
使用这款框架提供的ORM机制,对业务逻辑实现人员而言,面对的是纯粹的Java对象, 这一层与通过Hibernate实现ORM而言基本一致,而对于具体的数据操作,Hibernate会自动生成SQL 语句,而软件则要求开发者编写具体的SQL语句。相对Hibernate等 “全自动”ORM机制而言,这款框架以SQL开发的工作量和数据库移植性上的让步,为系统 设计提供了更大的自由空间。作为“全自动”ORM 实现的一种有益补充,框架的出现显 得别具意义。
原理
1. 软件和数据库的交互有两种方式:1.1 通过传统的框架提供的API:这是传统的传递statement Id和查询参数给sqlsession对象,使用sqlsession对象完成和数据库的交互;
提供了非常方便和简单的API,供用户实现对数据库的增删改查数据操作,以及对数据库连接信息和此框架自身配置信息的维护操作。
上述使用这款框架的方法,是创建一个和数据库打交道的sqlsession对象,然后根据statement Id 和参数来操作数据库,这种方式固然很简单和实用,但是它不符合面向对象语言的概念和面向接口编程的编程习惯。由于面向接口的编程是面向对象的大趋势,这款框架为了适应这一趋势,增加了第二种使用本软件支持接口调用方式。
1.2 将配置文件中的每一个
2. 软件的实现原理:
利用反射打通Java类与SQL语句之间的相互转换。
3. 软件的主要成员
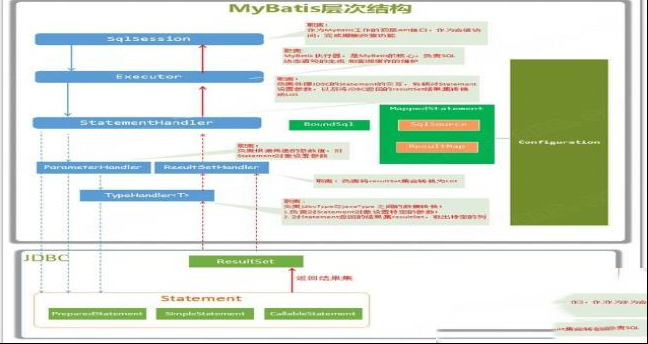
所有的配置信息都保存在Configuration对象之中,配置文件中的大部分配置都会存储到该类中
SqlSession 作为框架工作的主要顶层API,表示和数据库交互时的会话,完成必要数据库增删改查功能
执行器,是这款框架调度的核心,负责SQL语句的生成和查询缓存的维护
StatementHandler 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数等
ParameterHandler 负责对用户传递的参数转换成JDBC Statement 所对应的数据类型
ResultSetHandler 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合
TypeHandler 负责java数据类型和jdbc数据类型(也可以说是数据表列类型)之间的映射和转换
MappedStatement MappedStatement维护一条节点的封装SqlSource 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回BoundSql 表示动态生成的SQL语句以及相应的参数信息
mybatis一级缓存和二级缓存
①、一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。②、二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
1、一级缓存
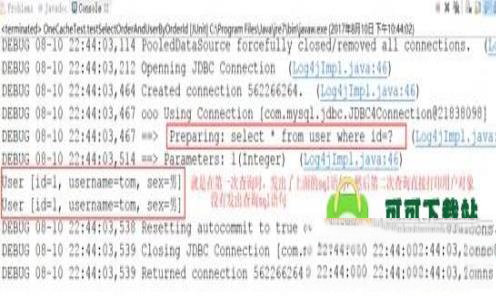
①、我们在一个 sqlSession 中,对 User 表根据id进行两次查询,查看他们发出sql语句的情况。
@Test
public void testSelectOrderAndUserByOrderId(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession = sessionFactory.openSession();
String statement = "one.to.one.mapper.OrdersMapper.selectOrderAndUserByOrderID";
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper.selectUserByUserId(1);
System.out.println(u1);
//第二次查询,由于是同一个sqlSession,会在缓存中查找查询结果
//如果有,则直接从缓存中取出来,不和数据库进行交互
User u2 = userMapper.selectUserByUserId(1);
System.out.println(u2);
sqlSession.close();
}
查看控制台打印情况:
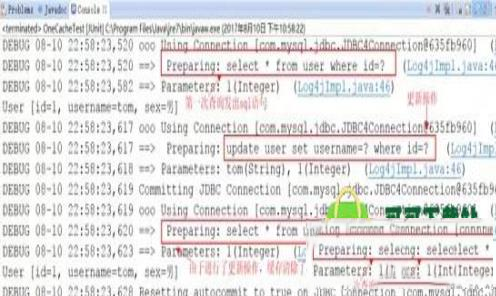
②、 同样是对user表进行两次查询,只不过两次查询之间进行了一次update操作。
@Test
public void testSelectOrderAndUserByOrderId(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession = sessionFactory.openSession();
String statement = "one.to.one.mapper.OrdersMapper.selectOrderAndUserByOrderID";
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper.selectUserByUserId(1);
System.out.println(u1);
//第二步进行了一次更新操作,sqlSession.commit()
u1.setSex("女");
userMapper.updateUserByUserId(u1);
sqlSession.commit();
//第二次查询,由于是同一个sqlSession.commit(),会清空缓存信息
//则此次查询也会发出 sql 语句
User u2 = userMapper.selectUserByUserId(1);
System.out.println(u2);
sqlSession.close();
}
控制台打印情况:
③、总结
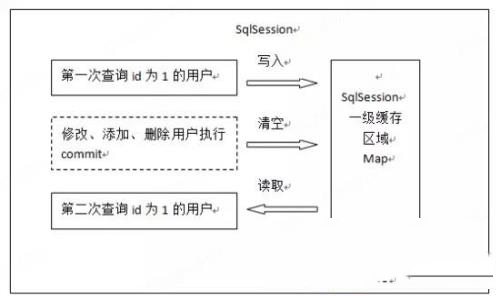
1、第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
2、如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
3、第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
2、二级缓存
二级缓存的原理和一级缓存原理一样,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于 sqlSession 的,而 二级缓存是基于 mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中。
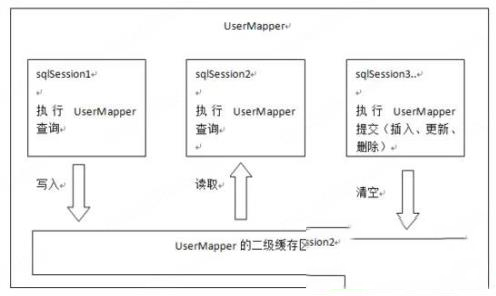
那么二级缓存是如何使用的呢?
①、开启二级缓存
和一级缓存默认开启不一样,二级缓存需要我们手动开启
首先在全局配置文件 mybatis-configuration.xml 文件中加入如下代码:
其次在 UserMapper.xml 文件中开启缓存
我们可以看到 mapper.xml 文件中就这么一个空标签,其实这里可以配置,PerpetualCache这个类是框架爱中默认实现缓存功能的类。我们不写type就使用框架中默认的缓存,也可以去实现 Cache 接口来自定义缓存。
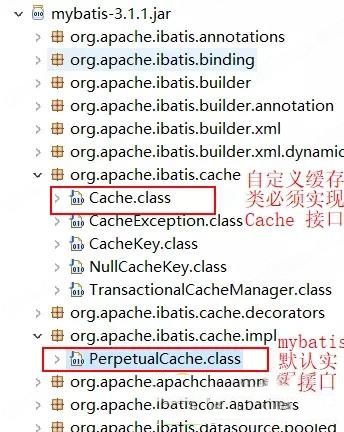
我们可以看到 二级缓存 底层还是 HashMap 架构。
②、po 类实现Serializable 序列化接口

开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以框架中的pojo都去实现Serializable接口。
③、测试
一、测试二级缓存和sqlSession 无关
@Test
public void testTwoCache(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
String statement = "com.ys.twocache.UserMapper.selectUserByUserId";
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper1.selectUserByUserId(1);
System.out.println(u1);
sqlSession1.close();//第一次查询完后关闭sqlSession
//第二次查询,即使sqlSession1已经关闭了,这次查询依然不发出sql语句
User u2 = userMapper2.selectUserByUserId(1);
System.out.println(u2);
sqlSession2.close();
}
可以看出上面两个不同的sqlSession,第一个关闭了,第二次查询依然不发出sql查询语句。
二、测试执行 commit() 操作,二级缓存数据清空
@Test
public void testTwoCache(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
SqlSession sqlSession3 = sessionFactory.openSession();
String statement = "com.ys.twocache.UserMapper.selectUserByUserId";
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
UserMapper userMapper3 = sqlSession2.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper1.selectUserByUserId(1);
System.out.println(u1);
sqlSession1.close();//第一次查询完后关闭sqlSession
//执行更新操作,commit()
u1.setUsername("aaa");
userMapper3.updateUserByUserId(u1);
sqlSession3.commit();
//第二次查询,由于上次更新操作,缓存数据已经清空(防止数据脏读),这里必须再次发出sql语句
User u2 = userMapper2.selectUserByUserId(1);
System.out.println(u2);
sqlSession2.close();
}
查看控制台情况:
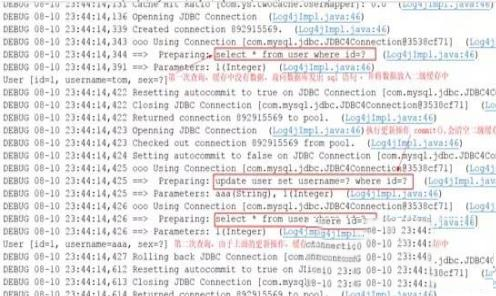
④、useCache和flushCache
软件中还可以配置userCache和flushCache等配置项,userCache是用来设置是否禁用二级缓存的,在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
select * from user where id=#{id}
这种情况是针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存,直接从数据库中获取。
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache=”true” 属性,默认情况下为true,即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
select * from user where id=#{id}
一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以我们不用设置,默认即可。
功能架构
我们把软件的功能架构分为三层:(1)API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
(2)数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
(3)基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑
常见问题
1、软件配置文件详解小编在软件的安装包内为用户提供了一个最为完整的软件主配置文件,包括properties属性、settings设置、typeAliases类型别名以及typeHandlers类型句柄等。有兴趣的用户可以进入浏览
2、mybatis sql语句
同样在这款软件安装包为有着最为完整的mybatis sql的动态sql语句,内容包括if标签、where、set、trim标签和set语句等。有需要的用户可以进入图区
3、MyBatis
使用这款框架提供的ORM机制,对业务逻辑实现人员而言,面对的是纯粹的Java对象, 这一层与通过Hibernate实现ORM而言基本一致,而对于具体的数据操作,Hibernate会自动生成SQL 语句,而这款框架则要求开发者编写具体的SQL语句。相对Hibernate等 “全自动”ORM机制而言,软件以SQL开发的工作量和数据库移植性上的让步,为系统 设计提供了更大的自由空间。作为“全自动”ORM 实现的一种有益补充,这款框架的出现显得别具意义。

下载地址
-
mybatisv3.3.0免费版
普通下载地址
资源服务器故障请点击上面网盘下载
其他版本下载
- 查看详情Navicat for MySQL16中文破解版 V16.0.14 免注册码版96.35 MB 简体中文22-06-22
- 查看详情联想M1520D打印机驱动 V1.0 官方版112.17 MB 简体中文22-06-22
- 查看详情Navicat 16 for SQLite破解版 V16.0.14 中文免费版44.15 MB 简体中文22-06-22
- 查看详情JSON转Access,MySQL,MSSQL,Oracle V1.0 下载53.3 MB 英文22-06-15
- 查看详情Navicat Premium 16破解版 v16.0.7(附安装教程)208MB 简体中文22-05-23
- 查看详情Advanced ETL Processor Professionalv6.3.6.7破解版142 MB 简体中文21-12-04
- 查看详情Valentina Studio prov10.1.1破解版77 KB 简体中文21-12-04
- 查看详情AccessToMsSql(数据库转换工具)v3.6官方版6.51 MB 简体中文21-12-04
人气软件

Navicat Premium 16破解版 v16.0.7(附安装教程)208MB
/简体中文
Navicat for MySQL16中文破解版 V16.0.14 免注册码版96.35 MB
/简体中文
Navicat for PostgreSQL破解版v15.0.6(附破解教程)69.7 MB
/简体中文
PLSQL Developer 12中文破解版(附注册码机汉化补丁)42.1 MB
/简体中文
SQLyog 64位v12.09中文破解版7.01 MB
/简体中文
Navicat Premium 12破解版中文(附破解补丁)48.2 MB
/简体中文
Navicat 16 for SQLite破解版 V16.0.14 中文免费版44.15 MB
/简体中文
SQLite Expert Professionalv5.3.0.350完美破解版83.3 MB
/简体中文
SQLyog 13v13.1.1中文破解版15.37 MB
/简体中文
HeidiSQL(MySQL数据库管理工具)v11.0.0.6081中文免费版19.6 MB
/简体中文
相关文章
-
无相关信息
查看所有评论>>网友评论共0条





 秀儿是你吗表情包高清版
秀儿是你吗表情包高清版 3dmark pro破解版 V2.24.7509 专业版
3dmark pro破解版 V2.24.7509 专业版 visual studio 2022破解版
visual studio 2022破解版 看门狗3军团破解版
看门狗3军团破解版 VX Search(文件搜索工具)v12.8.14官方版
VX Search(文件搜索工具)v12.8.14官方版 Microsoft Visual C++ 2019中文版(32/64位)
Microsoft Visual C++ 2019中文版(32/64位) FL Studio 21中文破解版 v21.3.2304
FL Studio 21中文破解版 v21.3.2304 DirectX修复工具官方正式版v4.0
DirectX修复工具官方正式版v4.0 HiBit Uninstaller(全能卸载优化工具)v2.3.25绿色中文版
HiBit Uninstaller(全能卸载优化工具)v2.3.25绿色中文版








精彩评论